P2P Search Engine
There seems to be increasing interest in the idea of using peer-to-peer (P2P) technology to rejuvenate search technology in light of Google‘s growing inability to link people with knowledge. There have been a couple of early attempts in this area, including Widesource (a P2P system that indexes people’s browser bookmarks), and Grub (similar to SETI@Home, it leverage user’s spare cycles and bandwidth to index the web). A new project in this area is a side project of Ian Clarke, of Freenet fame, called WebQuest. WebQuest allows the user to refine their searches. Most of these ideas parallel my own on how we might improve search engines’ capabilities to extract context from web pages. But it has a few drawbacks that I’d like to throw out there to people to consider and attempt to solve.
Systems such as Google use keyword extracting, and link analysis to attempt to extract context. The system is based on the assumption that users link to other sites based on context, and therefore it should be possible to figure out the context and rank a page’s content. Other sites, such as DMOZ use a system of human moderators who can understand a page’s context better and categorize it – incurring much manual labour in the process.
But why use such an indirect route? Users know what they’re looking for and, like the US Supreme Court on pornography, they’ll know it when they see it. Why not provide a mechanism for users to “close the loop” and provide direct feedback to the search engine, thus allowing other users to benefit from this extra input into the system?
This has been bugging me for a while, so I decided to throw together the following straw man for a P2P Search Engine that would allow users to leverage how other people “ranked” pages based on their response to search engine results.
This is an updated version of the original post, which pointed to PDF and Word versions of the proposal. As part of a recent web reorganization, I figured it would just be easier to include the proposal text in the post itself.
The Problem
Current popular search engine technology suffers from a number of shortcomings:
- Timeliness of information: Search engines index information using a “spider” to traverse the Internet and index its content. Due to the size of the Internet and the finite resources of the search engine, pages are indexed only periodically. Hence, many search engines are slightly out of date, reflecting the contents of a web page the last time the page was indexed.
- Comprehensiveness of information: Due to both the current size and rate of information expansion on the Internet, it is highly unlikely that current search engines are capable of indexing all publicly available sites. In addition, current search engines rely on links between web pages to help them discover additional resources; however, it is likely that “islands” of information unreferenced by other sites are not being indexed.
- Capital intensive: Significant computing power, bandwidth, and other capital assets are required to provide satisfactory search response times. Google, for example, employs one of the largest Linux clusters (10,000 machines).
- Lack of access to “deep web”: Search engines can’t interface with information stored in corporate web sites’ databases, meaning that the search engine can’t “see” some information.
- Lack of context/natural language comprehension: Search engines tend to be dumb, attempting to extract context in crude, indirect fashions. Search technologies, such as Google’s PageRank™, attempt to extract context from web pages only indirectly, through analysis of keywords in the pages and hyperlinks interconnections between pages.
The only available option to solve these problems is to develop a search technology that comprehends natural language, can extract context, and employs a massively scalable architecture. Given the exponential rate of information growth, developing such a technology is critical to enabling individuals, governments, and corporations to find and process information in order to generate knowledge.
The Proposed Solution
Fortunately, there already exists a powerful natural language and context extraction technology: the search users themselves. Coincidentally, they also are in possession of the resources required to create a massively scalable distributed architecture for coordinating search activities: a vast amount of untapped computational power and bandwidth, albeit spread across millions of individual machines.
What is required is a tool that allows users to:
- Index pages and generate meta-data as they surf the web.
- Share that meta-data with other search users.
- Search other users’ meta-data.
- Combine other users’ meta-data for a set of search terms with the user’s own opinion on how well the result matches the context of the set of search terms. This new meta-data is cached locally and shared with the network of users, thus completing the feedback loop.
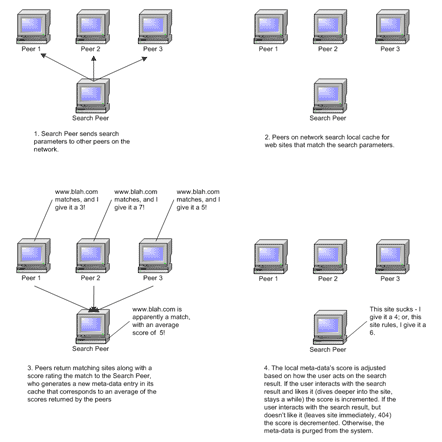
Implementation Hurdles
Insertion of Forged Meta-Data
Though users’ behaviour would “vote out” inappropriate material that got added to the peers’ cache of meta-data, the system would still be prone to attacks designed to boost certain sites’ rankings. A major design challenge would be to enable the system to withstand an attempt at forgery by a rogue peer or a coordinated network of rogue peers.
Search Responsiveness
As peers on the network will be spread across the Internet, accessing the network at a variety of connection speeds, the responsiveness of the network will be variable. Special consideration must be given to how to design the structure of the P2P network to incorporate supernodes to offset this characteristic.
Determining Surfer Behaviour
A major question that needs to be answered: how can we determine, through the users’ interaction with search results, their impression of a given search result? If a user goes to a site and leaves immediately, does this necessarily indicate the result was unsuitable and its score should be decremented? Or something else? If a user stays at a web page for a while, does it mean they like it, or that they went for coffee?
Generating a Site’s Initial Score
As a user surfs, an initial score must be generated for the sites they surf. How will this score be generated? Traditional search engines utilize reference checking in order to come up with a score for a web site; however, that technique is not practical when it’s only a single peer surfing a site. That leaves only more primitive techniques, such as keyword extraction, or other means to generate an initial score. However, we may be able to extract additional information based on how the user arrived at the web page. For example, if a user surfs from one site to another via a link, it might be possible to use the average score of the originating site as a base for generating the initial score.
Achieving Critical Mass
In early stages of development, the usefulness of the network for finding information will be directly proportional to the number of peers on the network. It’s a classis chicken and egg problem: without any users, no useful meta-data will be generated, and without the meta-data, no users will have an incentive to use the network. A possible solution to the problem would be to build a gateway to Google into each peer, to be used as a mechanism for seeding the network in its early development.
Privacy Issues
By tracking user’s surfing patterns, we are essentially watching the user and sharing that information with other users. Will users accept this? How can we act to protect the privacy of the user, while still extracting information that can be shared with other users?
Business Applications
The real question that needs to be answered, long before consideration can be given to the potential technical challenges, is: how can this technology be used to make money? A few proposals:
- Consumer Search Engine: The technology could be launched as an alternative to traditional search engines, using the technology to deliver well-targeted consumers to advertisers, and thus generate revenue.
- Internal Corporate Information Retrieval Tool: large corporations, such as IBM, could use a modified version of the technology to enable them to find and leverage existing internal assets.
- Others?
Conclusion
Yes, there are numerous holes in the idea (which I’ve highlighted in the document), but I don’t think any of them are insurmountable. The most important one, in my mind, is: how could you tweak this technology to build a real business? Though it would be possible to try to go the Google route (selling narrowly targeted advertising), I’m not sure that would be very smart considering not only the size of the existing competitor (Google) but also the number of other companies trying to bring down Google. It might be a good idea, in which case I’ve just shot myself in the foot by not patenting it, or a bad idea, in which case I’ll save myself the trouble of pursuing it. What are people’s thoughts on the merit of the idea (or lack thereof)?
Put up your ideas in HTML and perhaps I will read them….
Ditto Evan’s comment. Although I would read it if it were a PDF as well :p
Also, Google partially uses this in their algorithm as well — if a search for “ottawa baseball” has people consistently clicking on the third link result, it gets higher rankings.
There might be a way to refine this, in that Google doesn’t necessarily know that you “found what you were looking for” when clicking on the third link, so you would have to track the entire query, possibly with a browser toolbar that you can click a thumbs up/down for to communicate back with the search engine.
As regards the P2P aspect, I’m going to put some thoughts together (since I can’t read what you wrote) and put a post on my blog.
Mmm…plain links only:
http://www.bmannconsulting.com/node.php?id=342
I’ve updated the entry with a link to a HTML version of the document, for the M$ haters out there.
One more note I should add: I know that the problem of indexing the “deep web” was being tackled by the Gnutella guys working with Infrasearch – which eventually got bought by Sun and integrated into the JXTA Search team. Just thought I’d mention it.
Boris: I’m not certain that Google uses that technique, at least not anymore. If you do a “view source” on a search results page, you’ll see that all the search result links are normal links, not links that go to a redirect script on Google’s site. So, it would appear they have no way to track whether you click through search results.
That said, they may be doing that kind of tracking with the Google Toolbar – or they could do it fairly easily. Of course, if would require more back end horsepower to track user activities if they did.
I am not an M$ hater. I am a hater of the assumption that everyone uses MS Office/MS Media Player/etc and thus the slow creep of MS owning the net continues; sorry, comes to a close.
Your underlying assumption is that people search for the same things. Although this sounds reasonable, I’m not sure that it’s true. In certain cases, clearly this holds. For example, “What movies are playing now?”, “How does the Canon Powershot G3 compare?”, etc. Yet these are not the cases that search engines have difficulty with.
Today, I wanted to find information about entry and exit technique for kayaking on rocky coastlines. Googling for this information was very difficult, and required a great deal of “-class -course -tour” type terms. The likelihood of anyone else searching for this information, however, is very small, especially within a short time period.
Like any other branch of computer science, the shortcomings of search engines are in the special cases; the finding of information that is rarely accessed. Google rarely fails me, but when it does, I’m looking for something off the beaten path.
That’s a good point Ryan – the system is based on the assumption that people mean the same thing when they enter a number of keywords. This is exactly the reason Google fails for obscure searches, because no one has helped Google build that knowledge by linking to that information in that context (ie: no one’s thrown up a page on “kayak entry and exit techniques” and linked to a bunch of pages). Part of the problem also lies in the fact that Google indexes everything in a page, so if it’s a popular site, updated often, and includes those words, it’ll be returned as a result – hence the problem Google is facing with indexing blogs.
The problem is that the feedback signal to Google is extremely attenuated. When someone, such as yourself, finally finds a piece of information by picking through Google’s results and refining their search, that knowledge (“this is what I was looking for when I said ‘entry exit technique kayak’) is lost. Google throws away that knowledge, even though it could be tracked and incorporated into its database of knowledge.
Ryan’s observation implies additional required functionality: a method for allowing users to refine and sort through search results in a simple fashion, and augmenting the meta-data with the refinements. Basically this would say “hey, when someone searches for ‘exit entry technique kayak’ exclude pages that match the subsearch ‘class course tour’.
This idea reminds me of another proposal. Currently you can add a set of meta-tags to your web pages to guide search engines on what your page is about (a set of keywords and descriptions). This is failure-prone, as people have an incentive to lie in their keywords and descriptions. However, what if you could include a meta-tag giving a list of key words for which your site was not a match? This would allow you to tell a search engine “yeah, my page is about kayaking, but I don’t cover exit and entry techniques. Sorry!”
The negative keywords is an interesting concept…but it has been my experience that people do not optimize their sites to not be found.
As for meta-tags…they have not been used by search engines for years now, precisely because of the “gaming” of them.
Link tracking: I was actually thinking of the “sponsored links” that appear on the right hand side. You’re right on the “main” links. Yes, they do do some of that tracking with the Google toolbar if you accepted the “we will track you” option on install.
There’s actually stuff to find on the internet besides pr0n? Wow.
One note: though most search engines do not rely on meta-tags to generate their indices, they are not discounted entirely, even today. Google, from my understanding, still uses meta-tag information to guide its indexing process, but correlates data from meta-tags with keywords in the page, as well as keywords in pages linking to and linked from the page being indexed.
I’ve been thinking about this some more, and I found a number of other P2P search engine ideas on the net:
Opencola: A Canadian company out of Ontario which is working on using P2P to perform information retrieval. They have a unique approach in that you create “folders” into which search information is placed and automatically updated. Seems that they do utilize the results of previous searches by other users on the system: “Opencola searches the shared folders of other people in your organization for relevant results. It suggests documents based on the semantic match of their content and the rating of the peer it came from. Every result will be clearly marked with the peer name of the person you received it from.”
Pandango: A project by a Seattle company, i5 Digital, which was poised for success but seems to have disappeared instead. Anyone know anything about the project, where it went, and where its leader, Liad Meidar, is currently working?
In addition, there have been a number of other distributed search solutions, but nothing other than Opencola that has made it into a commercial product. Some even say that P2P search won’t work.
P2P search in an intranet context is much difference than a “Search the entire web” application.
Check out a Google search — the links to results now pass through Google first, thus (potentially) correlating search phrases and actual clicked links. Or lots of other nifty stuff that Google could do with the info..
Meta Tags: absolutely not used by Google in search rankings. Virtually no major engines use it for rankings. Sometimes used for the “Description” or other tags. Too lazy to look up the references right now…ok, ok — read http://www.searchenginewatch.com/webmasters/article.php/2167931 and lots of other stuff at Search Engine Watch.
However, I am a fan of using Dublin Core information, as it is just good information architecture.
I helped with some of the concepts behind NodeScan (http://www.nodescan.com/). Uses the Lucene search engine from Apple. Related to my AgentPeerSearch ideas, in that it distributes indexes so that each node contains a full index of the entire system.
JXTA would be a good platform to build distributed search on…
thanks for all your work i love mp3s and i know how there trying to take p2p form us. i just hope that its stays free and u dont have to pay to download. anyways thanks rock on dudes.
There exists such a p2p-based web search engine. Please look at http://www.yacy.net/yacy
You might want to check out http://search.minty.org and talk to the author, Murray Walker. He’s trying to hash out some of the same ideas.
I personally think an open, anonymous p2p web search engine as we’re imagining it is not viable. Think about those old “free-for-all links” pages from the early 90’s. Then think about the level of sophistication of spammers today.
My take is that we would be better served looking at how to help people create archives of the bits they want to keep, and help them share their archives with people they know personally.
Yeah, I wonder if the work we’ve seen lately with the blogosphere has actually transcended some of the need for this type of system. People are posting relevant content more frequently, search engines are indexing more frequently, and Bittorrent is becoming firmly embedded in the mainstream Internet…perhaps that is the real road to a true P2P search and information distribution system?
Cud you tell me if the protottype presenteed in http://www.yacy.net/yacy is similar to the ideas presented by you. Are there anyways we could improve the work of YaCY with regard to your view of a P2P based web searching engine ?
It’s not quite the same as what I had in mind, but it’s close. The purpose of the system I proposed was not only to use distributed peers to index the net, but to use collaborative filtering to improve search results by feeding individuals’ behaviour towards search results back into the index.